
目次
はじめに
こんにちは。てくますプロジェクトのYukkinです!
この記事は、てくますプロジェクトが開催した輪読会「ゼロから作るDeep Learning② 自然言語処理編」の活動記録です。
てくますプロジェクトは、「考える楽しさを探そう!」を合言葉に活動する、数学と情報科学の学習コミュニティです。各種イベントについては、ぜひ Connpass をご覧ください!
この輪読会は2023.05〜2023.09に開催しました。

本の紹介
リンク
『ゼロから作るDeep Learning』シリーズの2冊目です。自然言語処理について学びました。1冊目同様、分かりやすくて面白い本です。
活動記録
第1回 ニューラルネットワークの復習
2023/05/08に実施。
1章を読み進め、以下の内容を学習しました。
- ニューラルネットワークの復習
「ゼロから作るDeep Learning」で学んだ内容と同じです。ニューラルネットワーク、勾配法、誤差逆伝播法などの復習を行いました。

第2回 自然言語と単語の分散表現
2023/05/22に実施。
2章を読み進め、以下の内容を学習しました。
- 自然言語処理の概要
自然言語処理の目的は、人の話す言葉をコンピュータに理解させることであることを学びました。そのために、単語の意味をうまく捉えた表現方法を探す必要があります。 - シソーラスによる手法
単語をうまく表現する方法として、シソーラスによる手法を学びました。上位下位などの単語同士の関係をグラフで表現することで、単語間の繋がりを定義します。この単語ネットワークを利用することで、コンピュータに間接的に単語の意味を授けます。 - カウントベースの手法
単語をうまく表現する方法として、カウントベースの手法を学びました。各単語の周囲にはどのような単語が並んでいるかを調べ、各単語の登場回数によってベクトルを作ります。そのベクトルによって単語を表現します。
第3回 word2vec
2023/06/05に実施。
3章を読み進め、以下の内容を学習しました。
- 推論ベースの手法
単語をベクトルで表すために、ニューラルネットワークを使った推論ベースの手法があることを学びました。 - word2vec
推論ベースの手法として、文章の前後の単語から中央の単語を推論するCBOWや、文章の中央の単語から前後の単語を考えるskip-gramを学びました。
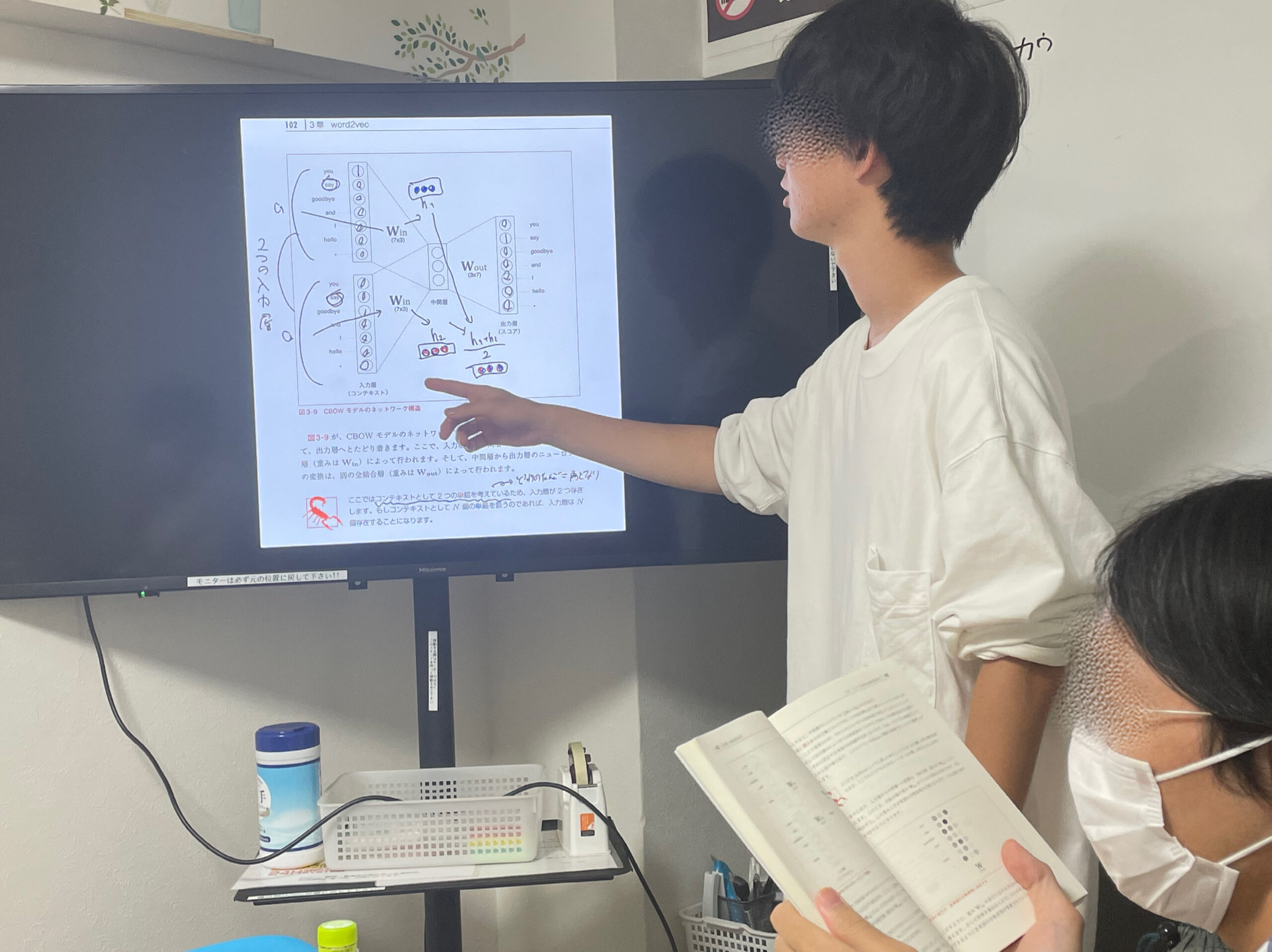
第4回 word2vecの高速化
2023/06/19に実施。
4章を読み進め、以下の内容を学習しました。
- word2vecのボトルネック
第3回で作成したシンプルなword2vecでは、巨大なコーパスを扱う際には時間がかかり過ぎてしまうことを学びました。 - Embeddingレイヤ
word2vecのボトルネックを解消する工夫の一つとして、Embeddingレイヤについて学びました。これは、行列の積の計算をするのをやめて、行列の特定行を抜き出す処理に書きかえるといった手法です。 - Negative Sampling
word2vecのボトルネックを解消する工夫の一つとして、Negative Samplingについて学びました。これは、多値分類ではなく二値分類で考えようといった手法です。
第5回 RNN
2023/08/07に実施。
5章を読み進め、以下の内容を学習しました。
- RNN(再帰ニューラルネットワーク)
一つ前の時刻の出力を次の時刻の入力に使うことで時系列データに対応したニューラルネットワークについて学びました。 - Truncated BPTT
RNNにおける誤差逆伝播法の計算量や勾配消失の課題に対処する方法を学びました。順伝播は繋げたまま、逆伝播は切断するといった考え方で、全体の繋がりを維持したまま、ブロック単位で逆伝播を行うことができます。
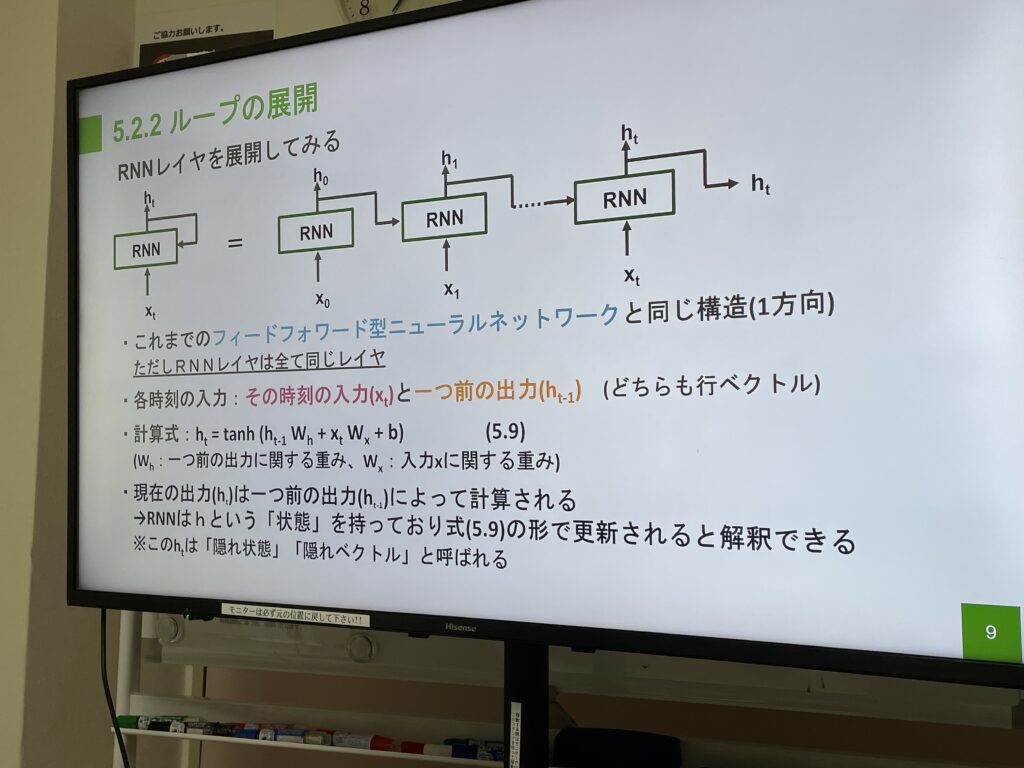
第6回 ゲート付きRNN
2023/08/21に実施。
6章を読み進め、以下の内容を学習しました。
- RNNの問題点
シンプルなRNNレイヤでは、時間がさかのぼるに従って、勾配消失、または、勾配爆発が起こることがほとんどです。それらの対処法を学びました。 - LSTM
勾配消失の対策として、ゲート付きRNNがあります。その中でも代表的なLSTMについて学習しました。LSTMには忘却ゲート、入力ゲート、出力ゲートがあります。この順にゲートを通っていくことで記憶を管理しています。
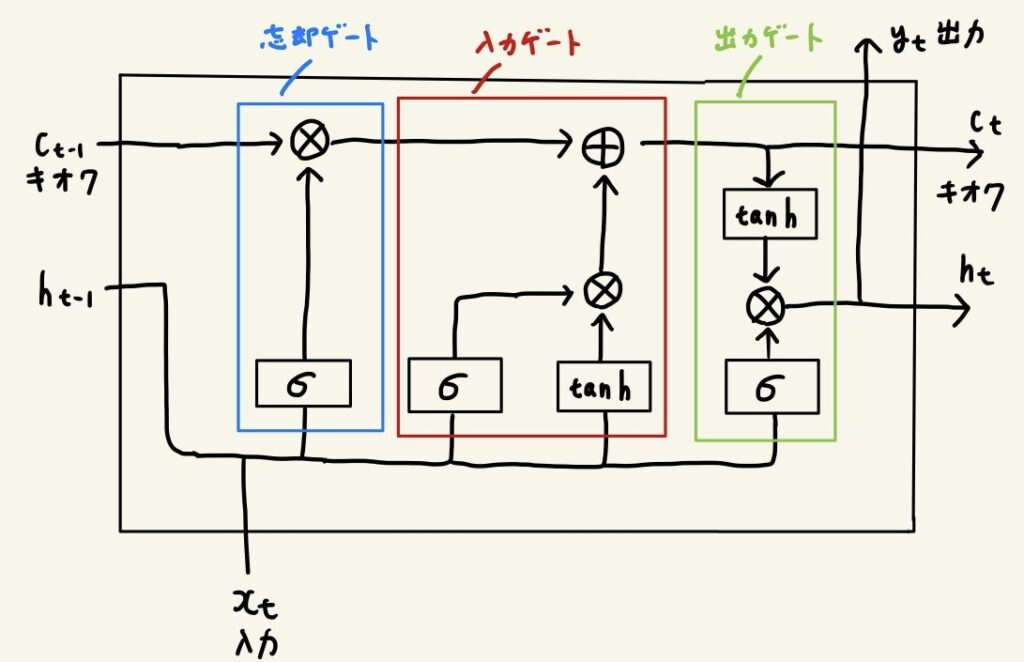
第7回 RNNによる文書生成
2023/09/04に実施。
7章を読み進め、以下の内容を学習しました。
- 文章生成
言語モデルを用いて、文章生成を行う方法を学びました。言語モデルは、これまで与えた単語から、次に出現する単語の確率分布を出力します。そのため、その確率に応じて、単語を次々と決めていくことで文章生成が可能です。 - seq2seq
翻訳や音声認識、質疑応答など、時系列データを別の時系列データに変換したいことがあります。そのためのモデルであるseq2seqを学びました。
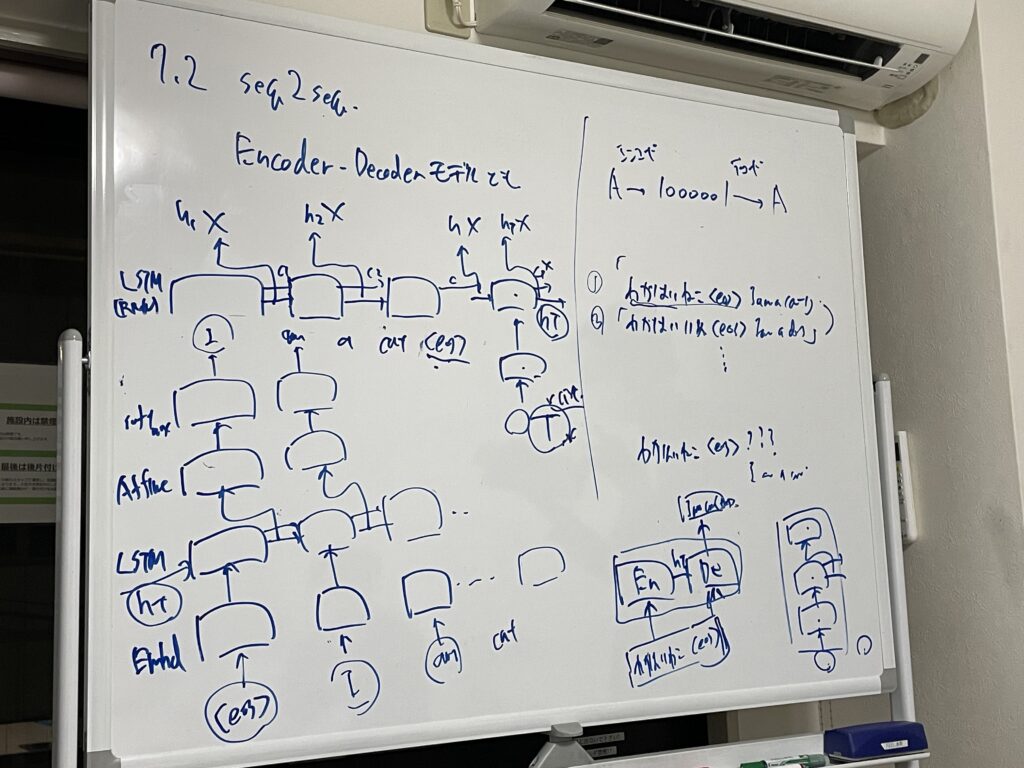
第8回 Attention
2023/09/25に実施。
8章を読み進め、以下の内容を学習しました。
- Attention
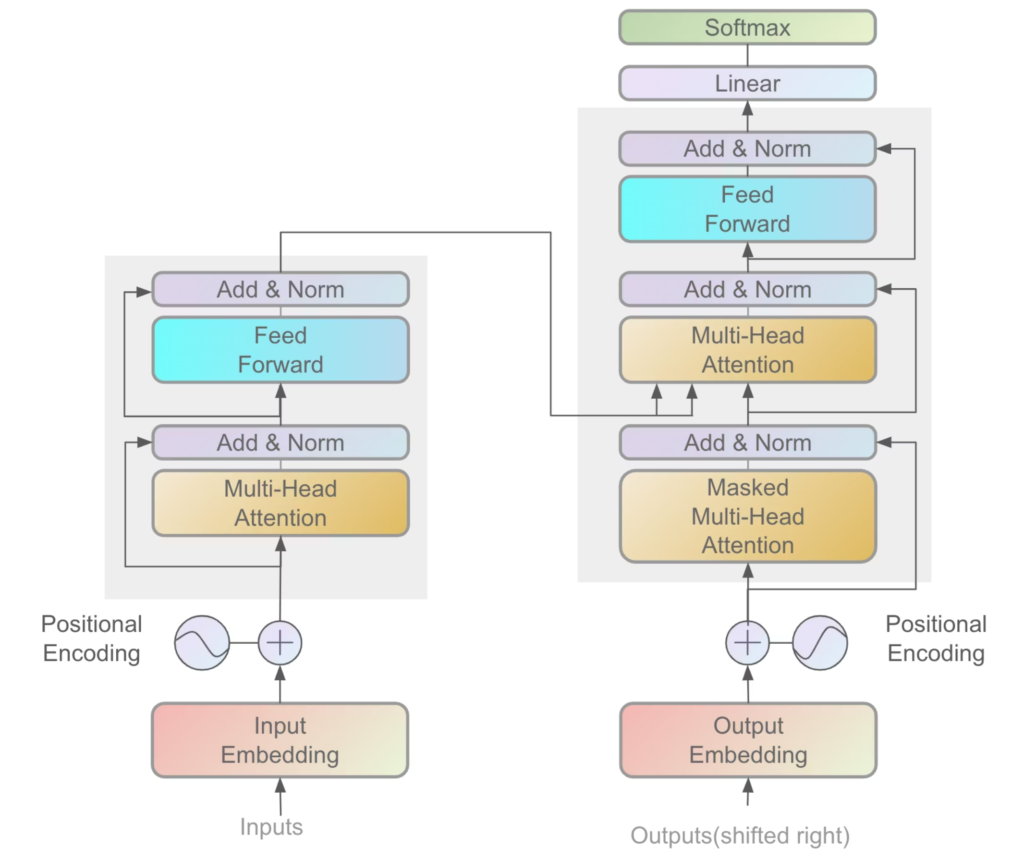
Transformerなどの最先端モデルで中心的な役割を持つAttentionについて学びました。Attentionは、入力系列の中で重要な情報に注目しながら処理を進める仕組みです。これまでのRNNやLSTMは、前後の文脈を順番に処理して情報を伝えていく方法でしたが、Attentionでは任意の位置の情報同士を直接関連づけることができます。
おわりに
この本を通して、word2vec、RNN、LSTM、Attentionなどの自然言語処理の流れを一連で理解することができました。
メンバーもさらに増え、8名で楽しく輪読会を進めることができています。
次回は引き続き、自然言語処理の本を読む予定です。
では、またね!



コメントを書く