
目次
はじめに
こんにちは。てくますプロジェクトのYukkinです!
この記事は、てくますプロジェクトが開催した輪読会「AIエンジニアを目指す人のための機械学習入門」の活動記録です。
てくますプロジェクトは、「考える楽しさを探そう!」を合言葉に活動する、数学と情報科学の学習コミュニティです。各種イベントについては、ぜひ Connpass をご覧ください!
この輪読会は2022.09〜2022.12に開催しました。

本の紹介
リンク
線形回帰、ロジスティック回帰、SVC、決定木、ランダムフォレスト、k-means、主成分分析などの機械学習の代表的な手法を、理論と実践、両方の観点で学べる本です。
分厚すぎず、機械学習の入門にとても良い本です!
活動記録
第1回 機械学習の概要、線形回帰
2022/09/05に実施。
1.1〜2.3を読み進め、以下の内容を学習しました。
- 機械学習の概要
機械学習とは何かを入り口に、教師あり学習・教師なし学習・強化学習といった基本的な分類や、代表的なタスクについて学びました。 - 線形回帰
最小二乗法の考え方を通して、データに最もよく当てはまる直線を求める回帰分析の基本を学びました。 - L1正則化とL2正則化
線形回帰モデルにおける過学習を抑える方法として、L1正則化・L2正則化の役割や違いを学びました。
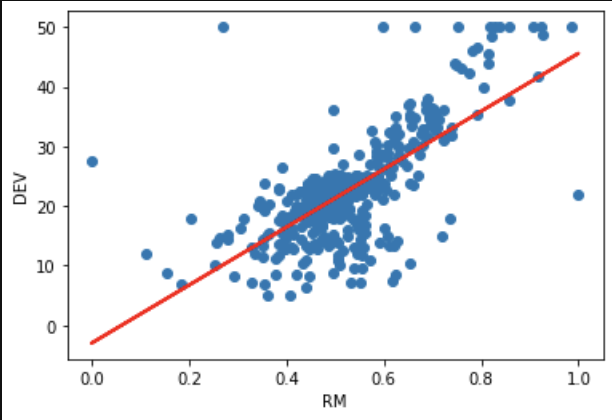
第2回 ロジスティック回帰、SVC
2022/09/26に実施。
2.4〜2.5を読み進め、以下の内容を学習しました。
- ロジスティック回帰
シグモイド関数を用いることで、二値分類を行う方法を学びました。 - SVC
マージンを最大化するという幾何学的な発想に基づき、分類する方法を学びました。

第3回 決定木、ランダムフォレスト
2022/10/17に実施。
2.6〜2.7を読み進め、以下の内容を学習しました。
- 決定木
情報利得や不純度を用いて、データを分割しながら分類を行う方法を学びました。 - ランダムフォレスト
複数の決定木を構築し、それらの予測結果を多数決で統合することで精度を高めるアンサンブル手法(バギング)を学びました。
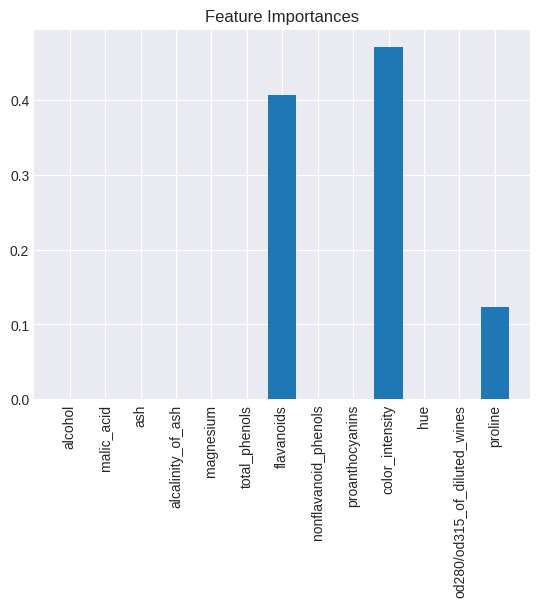
第4回 Naive Bayes、主成分分析
2022/10/31に実施。
2.8〜3.2を読み進め、以下の内容を学習しました。
- Naive Bayes
ベイズの定理を用いて、テキストデータを分類する方法を学びました。 - 主成分分析
共分散行列の固有値分解を通して、データの情報を保ちながら次元を削減する方法を学びました。線形代数学で学んだ固有値や対角化が、こんなところで活きてくるとは。

第5回 k-means、ガウス混合モデル
2022/11/14に実施。
3.3〜3.4を読み進め、以下の内容を学習しました。
- k-means
各データ点とクラスタの重心との距離を基準に、データをグループ分けするクラスタリング手法を学びました。 - ガウス混合モデル
複数のガウス分布を用いて、クラスタリングを行う方法を学びました。

第6回 勾配ブースティング決定木
2022/11/28に実施。
4.1〜4.3を読み進め、以下の内容を学習しました。
- 勾配ブースティング決定木
前のモデルが誤分類したデータを重視しながら、逐次的に決定木を構築していくアンサンブル手法(ブースティング)を学びました。 - エルボー法やシルエット分析
クラスタリングにおいて適切なクラスタ数を判断するための手法を学びました。

第7回 t-SNE、異常検知
2022/12/12に実施。
4.4〜4.5を読み進め、以下の内容を学習しました。
- t-SNE
高次元データを低次元に写像し、データの構造を可視化するための次元削減方法を学びました。 - 異常検知
正常データの分布や構造をもとに、通常とは異なる振る舞いを示すデータを検出する考え方と代表的手法を学びました。
おわりに
本書を通して、機械学習の基本的な考え方から、回帰・分類・クラスタリングといった代表的な手法まで、幅広く学ぶことができました。
次回はディープラーニングをテーマとした書籍を読み進めていきたいと思います。
では、またね!



コメントを書く