
この記事では、自然言語処理の歴史(〜2023年)について、登場人物二人の掛け合いとともに、振り返っていこうと思います。AIについてあまり知らない方にも、何とか雰囲気をつかんでいただけるように頑張って書いたので、ぜひ読んでいただけると幸いです。
目次
はじめに
シグマ「ふんふんふふーん」
オメガ「ハロー、シグマ。ごきげんだね」
シグマ「やあ、オメガ。今、ChatGPTで遊んでいたんだ」
オメガ「そうなんだね」
シグマ「すごいよなあ、ChatGPT。いったいどんな仕組みなんだろ。人間が裏で頑張って返事してくれているとしか思えないよ」
オメガ「確かにね! あ、そうだ。せっかくだしさ、今日は一緒に自然言語処理について学んでみる?」
シグマ「おー! いいね」
オメガ「自然言語処理について知るには、歴史を辿っていくのが一番だと思うから、そんな感じで話していくね」
シグマ「どんとこい」
ELIZA(イライザ)
オメガ「まずは、1966年に開発されたELIZAを紹介するね」
シグマ「1966年! そんな昔から、自然言語処理のAIがあったの?」
オメガ「そうだよ。第1次AIブームの頃だね。ELIZAは人間の心理療法師の役割を模倣したプログラムなんだ」
シグマ「どんなことができるの?」
オメガ「患者さんの悩み事を聞いて、返事することができるよ。まるで、人間と会話しているかのようだったことから、当時、多くの人々に深い衝撃を与えたんだ」
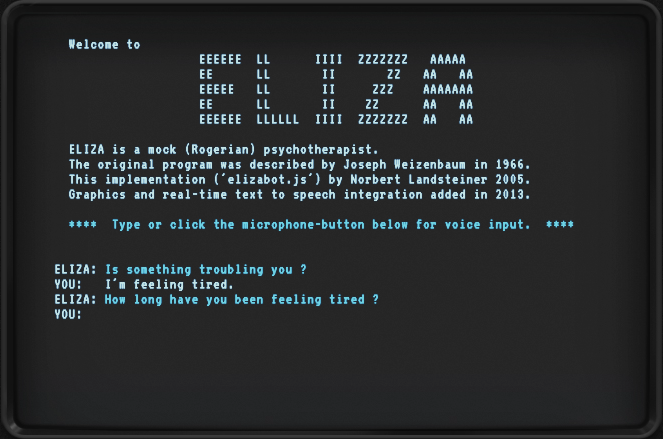
I’m feeling tired. (疲れを感じているんだ) というメッセージに対し、
How long have you being tired? (いつから疲れているのですか?) と返しています。
実際に動かしてみたい方は、ELIZA talkingを使ってみてください。
シグマ「すごい! チャットbotみたい」
オメガ「そうそう。ELIZAは元祖チャットbotだよ」
シグマ「へえー。いったい、どんな仕組みなんだろう……?」
オメガ「こう来たらこう返答するといった感じで、事前にパターンを決めているんだよ。たとえば、「I’m feeling ⚪︎⚪︎. 」という文章が来たら、「How long have you being ⚪︎⚪︎? 」と返答するといった感じだね」
シグマ「え? でもどんな質問が来るかなんてわからないよね。どんな質問が来ても大丈夫なようにパターンを決めるの、すっごく大変そう……」
オメガ「そうなんだよね。それに、予め決めたパターンに基づいて返事するだけだから、どうしても複雑な対話や文脈を理解して話すことは難しい……」
シグマ「なるほどなあ」
オメガ「とはいえ、ELIZA効果という言葉が生まれたくらい、当時の人に大きな衝撃を与えたことは確かなんだ」
シグマ「今だからこそ、チャットbotが身の回りにあるけど、1966年にこれを見ていたら、わたしもすごく驚いただろうなあ」
オメガ「だよね。こんな感じで、人が頑張ってパターン(ルール)を作成する方法を、ルールベースアプローチっていうよ」
Word2Vec
オメガ「次は、Word2Vecを紹介するね。時は進み、2013年」
シグマ「一気に進んだね!」
オメガ「もちろん、それまでにも色々あったんだけど、一気に進展し始めたのは、2010年代初頭からだよ。ディープラーニングの進展とともにね」
シグマ「ディープラーニングって、ルールを自動で学習できるんだよね?」
オメガ「そうだね。人がルールを作成するルールベースアプローチに対し、機械がルールを学習する方法を、機械学習と呼ぶよ。そして、ディープラーニングも機械学習の一種なんだ」
シグマ「ふむふむ」
オメガ「さて、Word2Vecは単語をベクトル(数値の組)で表現するための技術だよ」
シグマ「単語をベクトルに? どうしてそんなことをするんだろう」
オメガ「コンピュータを使う上で、数値のほうが都合がいいからだね。次の問題は知っているかな?」
king – man + woman は?
シグマ「え、なぞなぞ? 王から男性が引かれて、女性が足されているから、答えは……女王?」
オメガ「正解! queenだよ。単語を数値化できるということは、計算でこの式を確かめることができる」
シグマ「すご!!」
オメガ「単語をベクトルで表現する際、よく似た単語はよく似たベクトルになるように、反対の意味の単語は反対向きのベクトルになるように、工夫されていることがポイントなんだ」
シグマ「ベクトルが単語の意味を反映しているってことか」
オメガ「そうそう。それでね、Word2Vecを実現するための有名な手法が、CBoWとSkip-Gramだよ」
シグマ「なんかいろいろ出てきたなあ」
オメガ「ここではCBoWについて紹介するね。CBoWは簡単に言うと、周りの単語を見て、欠けている単語を予測する方法だよ。そうだね、次の文章を考えてみよっか」
私は公園で___を楽しむ
シグマ「わたしなら、かくれんぼかな」
オメガ「(どうでもいいけど)そうなんだ……」
シグマ「どうしてこういった穴埋め問題を考えることで、単語をベクトルで表現できるようになるんだろう?」
オメガ「順を追って説明していくね。まず、CBoWのアイデアは、単語の意味はその周囲の単語によって決まるという考えに基づいているんだ」
シグマ「ふむふむ」
オメガ「今回の例では、空欄の前後2単語までを周囲として考えるね」
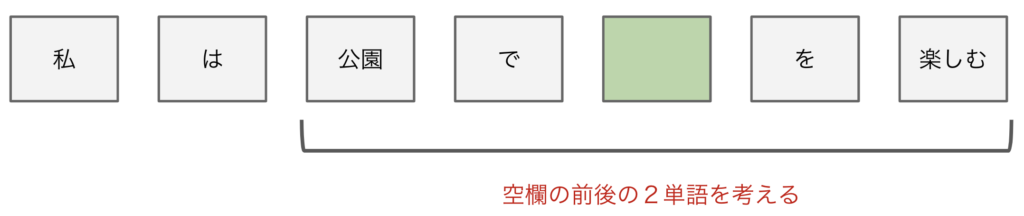
シグマ「なるほど」
オメガ「そして、ディープラーニングを用いてこの穴埋め問題を学習する」
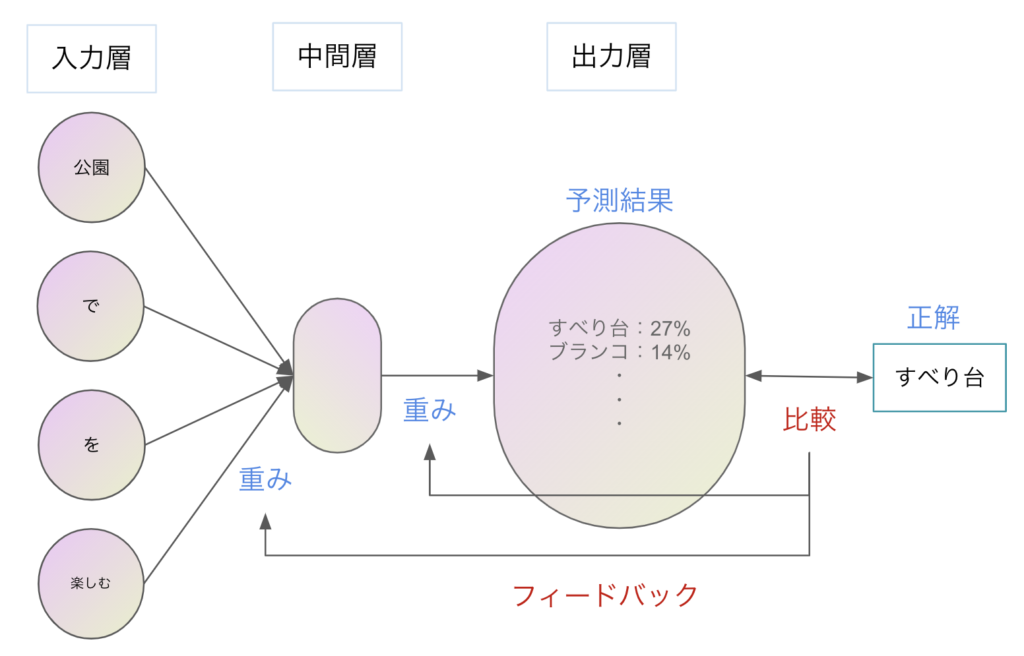
シグマ「でたな、ディープラーニング……」
オメガ「そこまで身構えなくていいよ。入力層には、空欄の前後2単語までが入っている。そして、中間層を経て、出力層では、各単語が空欄にあてはまる確率を予測結果として出力している」
シグマ「ふむふむ」
オメガ「ディープラーニングにおける学習とは、予測結果が正解に近づくように、重みを更新していくことだよ」
シグマ「なるほど。図には2種類の重みがあるね」
オメガ「そうそう。そのうち、入力層から中間層に至る際に使われているほうの重み。これこそが、単語のベクトル表現なんだ」
シグマ「???」
オメガ「穴埋め問題を学習する過程で、副産物として生まれる重みが、単語のベクトル表現にあたるということだよ」
シグマ「中々ややこしいなあ」
オメガ「そうだね。ともあれ、これで単語をベクトルで表現できるようになったよ」
RNN
オメガ「さて、今度は次の文章を考えてみよっか」
シグマが公園で遊んでいると、オメガがやってきた。オメガは___にハローと声をかけた。
シグマ「空欄に入る言葉は、シグマだね」
オメガ「その通り。ただ、CBoWでは、この問題を解くことは難しいんだ」
シグマ「なるほど……。CBoWは前後N文字にどんな単語があるかをもとに考えているから、文脈や文章の時系列っぽさをうまく捉えられないんだね」
オメガ「そういうこと。そこで、RNNの出番なのだよ」
シグマ「あーる、えぬ、えぬ」
オメガ「Reccurent Neural Networkの略だね。Reccurentは循環するという意味だよ」
シグマ「循環するニューラルネットワーク……」
オメガ「RNNの考え方自体は昔からあったんだけど、強く注目されるようになったのは、Word2Vecと同時期なんだ」
シグマ「へええ」
オメガ「では、RNNの図を見ていこうね」
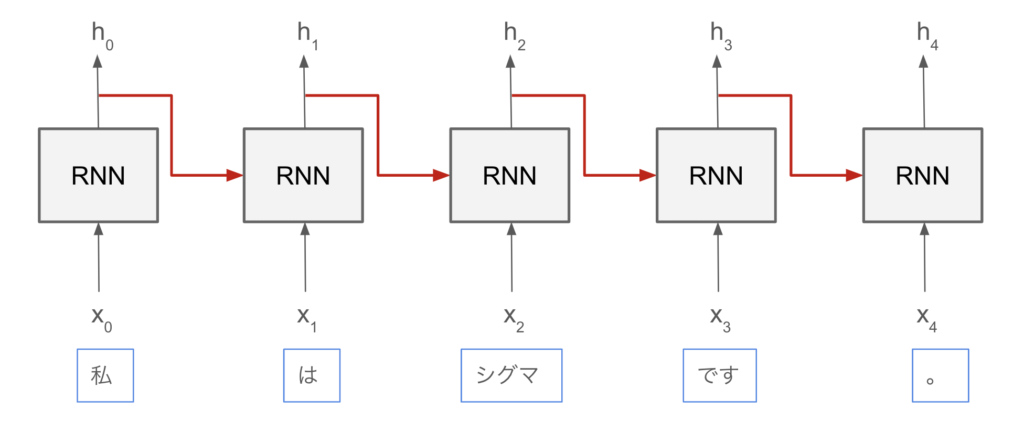
オメガ「RNNのポイントは、何といっても赤い矢印の部分だよ」
シグマ「RNNで出力された値が、次のRNNの入力に使われているな」
オメガ「その通り。これによって、過去の情報を受け継いでいくことで、時系列っぽさを学習しているんだよ」
シグマ「なるほどー」
オメガ「ただ残念なことに、RNNはあんまり精度が良くないんだよね」
シグマ「そうなんだ……」
オメガ「ディープラーニングにおける学習とは、予測結果が正解に近づくように、重みを更新していくことだって、さっき言ったよね」
シグマ「うん」
オメガ「この重みの更新は後ろから行なっていくんだ。これを誤差逆伝播法という」
シグマ「後ろ側からフィードバック結果を受けて重みを補正していくということだね」
オメガ「そうそう。ただ、長い時系列のRNNだとそれが難しいんだ。時系列の後ろから重みの更新を行なっていく中で、フィードバックの力がどんどん弱くなってしまうんだよね」
シグマ「うーん、伝言ゲームみたいな感じなのかな。伝えていくにつれて、どんどんもとの情報が少なくなっていく」
オメガ「イメージはそんな感じかな。これを勾配消失というよ」
シグマ「これのせいで、あんまり精度がよくないんだな」
オメガ「そういうこと。それでね、この問題を何とかするために……」
シグマ「また新しいものが登場するんだね」
オメガ「その通り!」
LSTM
オメガ「ということで、次はLSTMを紹介するよ! これも実は、RNNの一種なんだ」
シグマ「ふむふむ」
オメガ「LSTMは、Long Short-Term Memoryの略だよ。長・短期記憶」
シグマ「長期記憶なのか、短期記憶なのか、はっきりしない名前だな」
オメガ「短期記憶を長い間保存できるという意味だと思ってもらっていいよ」
シグマ「なるほどー」
オメガ「では、LSTMの図を見ていこうか」
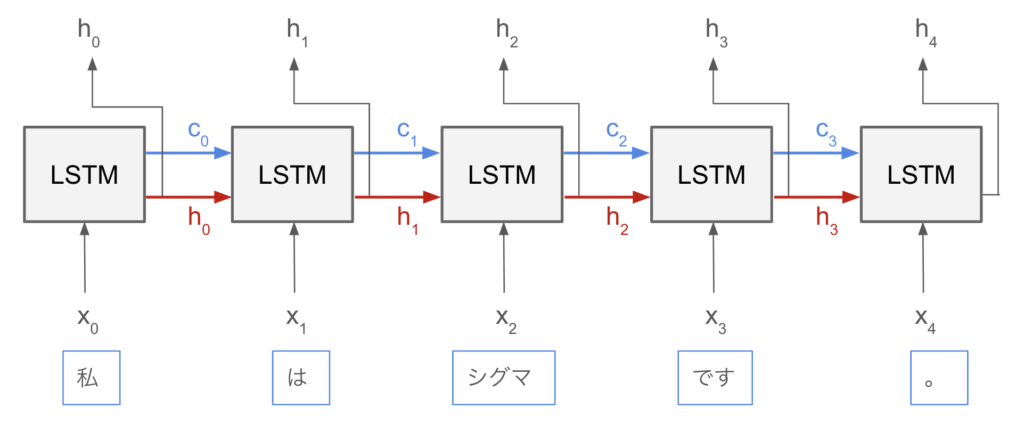
シグマ「LSTMでは、前の時刻から受け取る情報が、cとhで2種類になっているね」
オメガ「そうそう。赤い矢印はその場で使いたい情報の受け渡しに使っていて、青い矢印は長期的に保存したい情報の受け渡しに使っているんだ」
シグマ「短期記憶のラインと長期記憶のラインって感じかな。そんなことが出来るんだね」
オメガ「そのための仕組みとして、LSTMの内部には、忘却ゲート、入力ゲート、出力ゲートという3つのゲートが備わっているよ」
シグマ「なんかちょっとかっこいいな」
オメガ「そう? まず、忘却ゲートを説明するね。これは、長期記憶のうち、どの記憶をどの程度、次に引き継ぐかを制御しているゲートだよ」
シグマ「すべて引き継ぐんじゃないの?」
オメガ「現在の記憶(cやh)と、入力としてやってきた単語(x)をもとに、使わないと判断した記憶はここで削除するよ。だから、忘却ゲートって名前なんだ」
シグマ「なるほど……」
オメガ「次に、入力ゲート。これは、どの情報を新たに記憶に追加するかを制御しているゲートだよ」
シグマ「ふむふむ」
オメガ 「最後に、出力ゲート。これは、長期記憶と短期記憶を仕分けるゲートだよ」
シグマ「なるほど」
オメガ「LSTMは、忘却ゲート→入力ゲート→出力ゲートという3つのステップで、記憶をうまく管理しているってことだね」
シグマ「新しい単語が入ってきたら、もう忘れていいかなってことは記憶から忘れて、新たに覚えた方がいいかなってことは記憶に追加して、最後に長期記憶と短期記憶に分けているってわけだ」
オメガ「そうそう」
シグマ「なんかLSTMって人間的だなあ」
オメガ「確かにそんな感じがするかも」
シグマ「ところでさ、LSTMではRNNであった問題は起きないの? 勾配消失ってやつ」
オメガ「勾配消失が起きにくいように、工夫されているよ。ただ、それを説明するのはちょっと大変だから、今はそういうものなんだって思ってもらえると嬉しいな」
シグマ「オッケー」
オメガ「さて、LSTMがどういう感じで使われているのかの例として、翻訳を紹介しておくね」
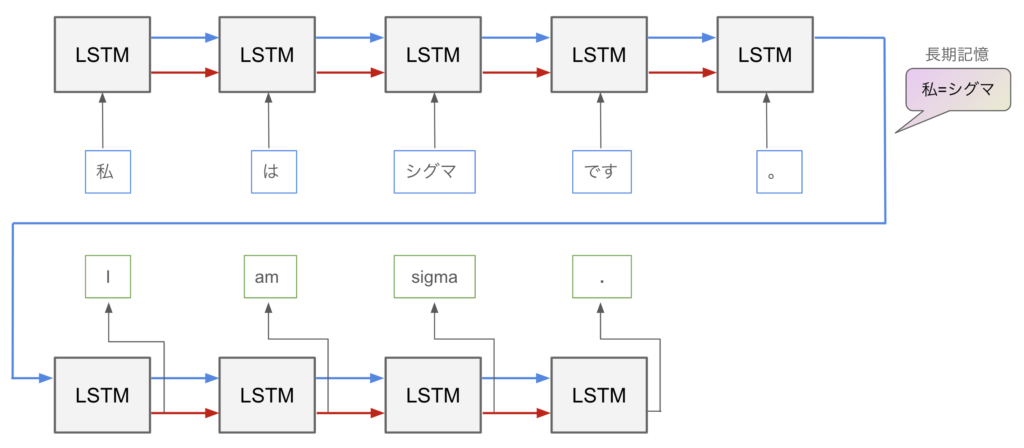
シグマ「日英翻訳だ!」
オメガ「上段はEncoderと呼ばれる部分で、日本語文をベクトルに変換しているよ。一方、下段はDecoderと呼ばれる部分で、上段から引き継いだベクトルを英文に変換しているんだ」
シグマ「すごい! 翻訳ってこんな感じで行われていたんだなあ」
Transformer
オメガ「さて、最後にTransformerを紹介するね」
シグマ「あと一息!」
オメガ「もう少しだけ頑張っていこうね。さて、Transformerは、2017年に『Attention is All You Need』というタイトルの論文で発表されたよ」
シグマ「Attention is All You Need」
オメガ「Transformerはね、脱RNNを目的としているんだ」
シグマ「脱RNN!」
オメガ「RNNやLSTMだと、順番に処理を行っていく関係上、並列処理が得意なGPUの能力を十分に使えないんだ。だから、RNNやLSTMを用いずに、代わりにAttentionというメカニズムを使おうと考えた」
シグマ「だから論文のタイトルにもAttentionって言葉が入っているんだな」
オメガ「そうだね。このAttentionこそが、Transformerで中心的な役割を果たしているんだよ」
シグマ「ふむふむ」
オメガ「では図を見てみようか」
シグマ「ヒェッ……」
オメガ「今回は深入りしないから大丈夫だよ。Transformerもさっきの翻訳と同じで、EncoderとDecoderをもつモデルなんだ。左側がEncoder、右側がDecoder」
シグマ「Attentionという言葉が登場しているね。それに、RNNやLSTMは登場していない」
オメガ「まさに脱RNNだね。さて、ここからはAttentionがどういうものかを説明するよ」
シグマ「Attention……。注目って意味だよね?」
オメガ「そうそう。ある単語が入力として与えられたとき、文章中の別のどの単語に注目するべきかを調べるんだ。これによって離れた位置の情報も適切に取り入れることができて、より深く文脈を捉えることができるんだよ」
シグマ「へええ。どうやって注目するべき単語を調べるんだろう?」
オメガ「似ている単語=注目するべき単語と考えるんだ。そのために、単語どうしの類似度を調べているね。ベクトルとベクトルの類似度は内積を使って調べることができる」
シグマ「なるほど……! あ、すごいことに気づいてしまったよ」
オメガ「どうしたの?」
シグマ「この処理は並列化できるんだね! <ある単語が入力として与えられたとき、文章中の別のどの単語に注目するべきかを調べる>ことは、すべての入力に対し、並列で考えることができる」
オメガ「よく気づいたね! これによって効率的に学習を進められるというわけだね」
シグマ「えへへ」
オメガ「さて、Transformerを活用したモデルを2つ紹介するよ」
シグマ「うんうん」
オメガ「まず、一つ目はBERT。2018年にGoogleが発表した自然言語処理モデルで、翻訳、文書分類、質問応答などの様々なタスクにおいて当時の最高スコアを叩き出したんだ」
シグマ「すごい!」
オメガ「これまでは、タスクごとに様々なモデルを使い分けていたんだけど、BERTはなんと幅広いタスクに対応できるんだよ」
シグマ「万能ってこと?」
オメガ「そうだね。BERTは、まず大規模データで事前学習した後、タスクに応じてファインチューニングするといった学習法なんだ。はじめにしっかり事前学習をしておくことで、ファインチューニングは少しで済むよ」
シグマ「なるほど。事前学習したBERTがすべてのタスクの土台にあることで、個別タスクに対しての調整は最後の少しだけで済むってことか。例えるなら、スポーツの基礎をしっかり身につけている人は、どのスポーツもすぐ上手くなるみたいな感じかな?」
オメガ「そういうことだね。さて、モデルの二つ目を紹介するよ」
シグマ「うん」
オメガ「二つ目はGPT。同じく2018年にOpenAIによって開発されたモデルだよ」
シグマ「GPT! これってChatGPTのGPTだよね?」
オメガ「そうだよ。GPTは、Generative Pre-trained Transformerの略なんだ」
シグマ「GPTのTは、TransformerのTだったのか!」
オメガ「そうだね。あと、generativeは生成力をもつという意味だよ。GPTはその名の通り、文章を生成する能力が非常に高いんだ」
シグマ「生成される文章が本当に自然で、すごく大きな話題になったよね」
オメガ「世の中を大きく変えた、そしてこれからも変えていく技術だろうね」
シグマ「BERTとGPTはどちらもTransformerを活用しているけど、どのような違いがあるの?」
オメガ「BERTはTransformerのEncoder部分をもとにしていて、文脈を理解することが得意だよ。それに対し、GPTはTransformerのDecoder部分をもとにしていて、文章生成が得意なんだ」
シグマ「なるほど……」
オメガ「わたしの話はここまでだよ。お疲れさま」
シグマ「ありがとう! お疲れさま」
おわりに
後日談
オメガ「ハロー、シグマ。また、ChatGPTを触っているの?」
シグマ「やあ、オメガ。今ちょうど、オメガに教えてもらった自然言語処理の歴史を、忘れないように記事としてまとめていたところなんだ。けど、記事のいいタイトルが思いつかなくてね」
オメガ「それで、ChatGPTに聞いてるんだ?」
シグマ「そういうこと。……あのさ」
オメガ「どうしたの?」
シグマ「この前、オメガから自然言語処理について色々教えてもらってさ、身の周りの技術にもっと敬意を払いたいと思ったんだ」
オメガ「うんうん」
シグマ「それに、もっともっと学んでみたいって思った! ありがとう、オメガ」
オメガ「どういたしまして。これからも色んなことを一緒に学んでいこうね」
シグマ「そうだな」
オメガ「それで、ChatGPTはいいタイトルをくれた?」
シグマ「自然言語処理の歴史を巡る冒険ーーだってさ」