
目次
はじめに
てくますプロジェクトでは、てくますゼミと呼ばれる輪読会を隔週で開催しています。
少人数であーだこーだ議論しながら、考える楽しさを分かち合う、ゼミのようなコミュニティです。主に、AIなどの「IT × 数学」領域について学習しています。

現在は「ゼロから作るDeep Learning② 自然言語処理編」という本を読み進めています。
今回は本書第3回の輪読会ということで、3章を読み進めました!
本記事では、今回の勉強会で学んだことをざっくりと紹介していきます。
学習内容
推論ベースの手法
単語をベクトルでうまく表すことを、単語の分散表現と言います。
前回は単語の分散表現を得るために、カウントベースの手法を用いました。
カウントベースの手法では、コーパスが大きくなると、その分、扱う行列も大きくなります。しかし、巨大な行列に対し、SVDを行うことは現実的ではありません。
そのため、今回は新たに推論ベースの手法(word2vec)を学びました。この手法はニューラルネットワークを使っており、ミニバッチでデータを小分けして考えることができます。
word2vec
word2vecもカウントベースの手法と同様に、「単語の意味は、周囲の単語によって形成される」といったアイデア(分布仮説)を使います。ただし今回のタスクは、推論です。
- CBOW
文章の前後の単語から中央の単語を考える手法です。
例: you ? goodbye and i say hello .
前後の you と goodbye から ? に何が入るかを学習/推論します。 - skip-gram
文章の中央の単語から前後の単語を考える手法です。
例: ? say ? and i say hello .
say から前後の ? に何が入るかを学習/推論します。
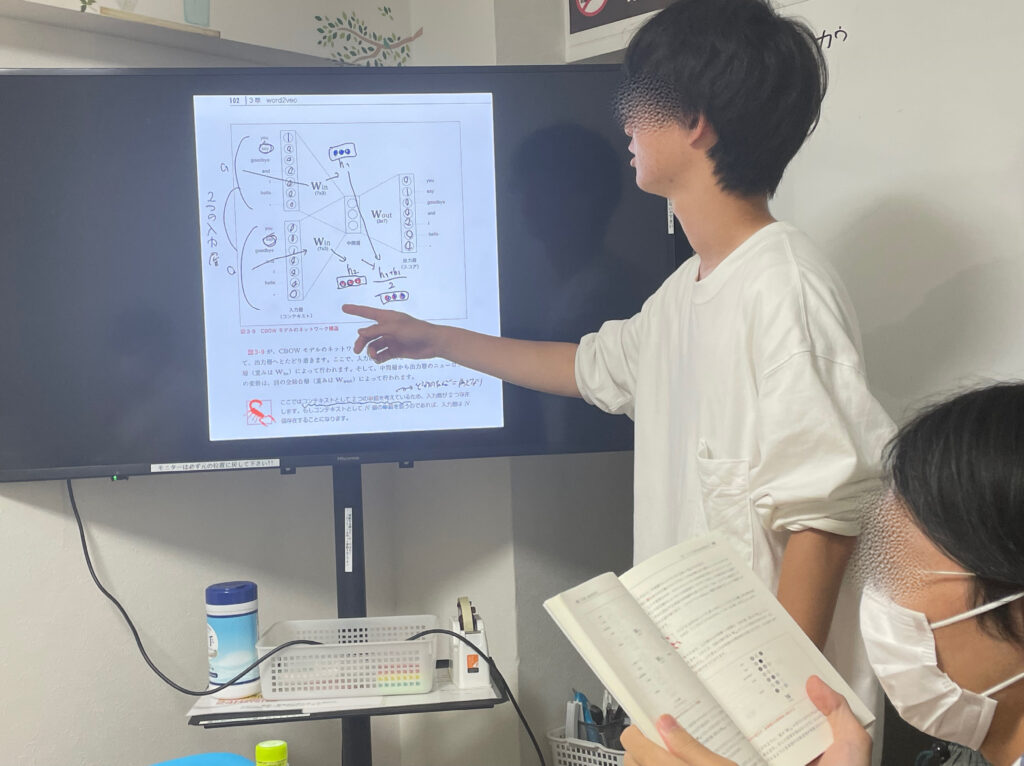
CBOWの場合、入力層は前後の単語のone-hot表現であり、出力層はコーパス内の各単語が現れる確率となります。これまでのニューラルネットワークと異なり、入力層が複数あるのが特徴です。
上の画像について、小さくて申し訳ありませんが、
入力層→(W_inと全結合)→中間層→(W_outと全結合)→(ソフトマックス関数)→出力層
となっています。損失関数は交差エントロピー誤差関数です。
そして、この学習の中で得られる重みパラメータW_inこそが単語の分散表現にあたります。
最後に
思っていたより簡単に、自然言語処理にディープラーニングを適用することができました。しかし、このままではまだ大きなデータセットは扱えないようです。
ということで、次回は「word2vecの高速化」!
次回も楽しみです。では、またね。






