
目次
はじめに
てくますプロジェクトでは、てくますゼミと呼ばれる学習会を開催しています。
少人数であーだこーだ議論しながら、考える楽しさを分かち合うことを大切にしています。

現在は「AIエンジニアを目指す人のための機械学習入門」という本を読み進めています。
今回は本書第2回の輪読会ということで、2.4〜2.5を読み進めました!
本記事では、今回の勉強会で学んだことをざっくりと紹介していきます。
学習内容
ロジスティック回帰
ロジスティック回帰は教師あり学習の一つで、「回帰」と名前が付いていますが、分類タスクで用いられる手法です。分類とは入力データを与えたとき、対応する出力データとして、ラベルデータを予測する学習手法です。
ロジスティック回帰のカギはシグモイド関数です。
\(\displaystyleσ(x)=\frac{1}{1+e^{-x}}\)
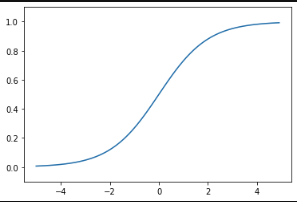
シグモイド関数を用いることで、すべての実数を0〜1の範囲の値に変換することができます。
0〜1の値ということは確率として解釈できます。この確率により分類を行います。
関数を \(σ(ax+b)\) と一般化し、\(a\) や \(b\) の値を変化させることで、グラフの形は変わります。
どのような \(a\) や \(b\) の値にすることで、もっとも今回のデータに当てはまりのよいグラフになるかを学習しています。
テキストでは実際に、会員を継続するかしないかを予測するロジスティック回帰を実装しました!
SVC

SVC(Support Vector Machine Classification)も分類タスクで用いられる教師あり学習の手法です。SVCではマージンが最大となるような境界線を引くことを考えます。
マージンとは、クラスを分ける境界線に対して、それぞれのクラスで最も近いデータまでの距離のことです。
つまり、最も近い点までの距離がなるべく遠くなるように境界線を引くということですね。
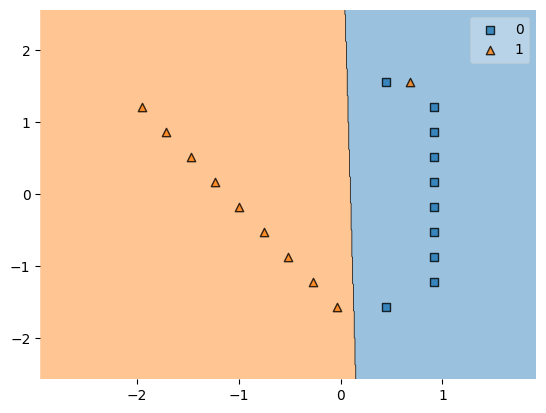
しかし、データは綺麗に線形分離できるとは限りません。下の図では、青い領域に▲が紛れ込んでしまっています。
誤分類に対しペナルティを与えることで、ペナルティも考慮したうえでの境界線を考えることができます。下の図では、ペナルティを小さくするために、誤分類の▲が先ほどより境界線に近づいていますね。
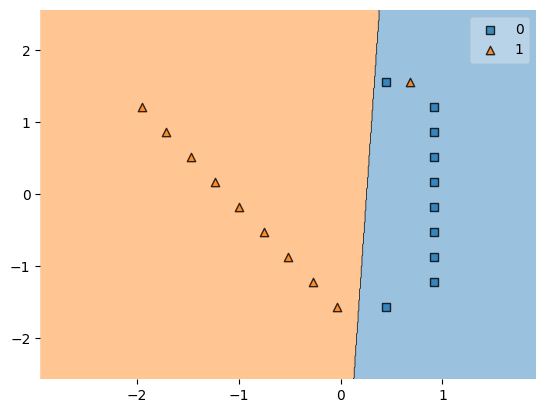
SVCは境界線に最も近い点や誤分類の点しか関わってこないので、何とも大胆な方法だなと思いました。
最後に
今回は分類の2つの手法について学習しました。
あと、参加メンバーが2人から3人に増えました。嬉しいです! これからもっとメンバーが増えていくといいですね。
次回も引き続き、分類について学んでいきます。
では、また!










