
目次
はじめに
てくますプロジェクトでは、てくますゼミと呼ばれる輪読会を隔週で開催しています。
少人数であーだこーだ議論しながら、考える楽しさを分かち合う、ゼミのようなコミュニティです。主に、AIなどの「IT × 数学」領域について学習しています。

現在は「ゼロから作るDeep Learning」というディープラーニングの有名な本を読み進めています。
今回は本書第5回の輪読会ということで、6章を読み進めました!
本記事では、今回の勉強会で学んだことをざっくりと紹介していきます。
学習内容(6章)
パラメータの更新方法
損失が小さいパラメータにするために、勾配を利用して現在のパラメータから新しいパラメータに更新していくのが学習です。
この章ではまず、パラメータの更新方法をいくつか学びました。
- SGD(確率的勾配降下法)
前章までで用いてきた方法です。
$$W\leftarrow W-\eta\frac{\partial L}{\partial W}$$
\(W\):重みパラメータ,\(L\):損失関数,\(\eta\):学習係数,\(\leftarrow\):右で左を更新する - Momentum
勾配によって窪地にボールが転がっていく様子を再現した方法です。
$$v\leftarrow \alpha v-\eta\frac{\partial L}{\partial W}$$
$$W\leftarrow W+v$$
\(v\):速度に対応する変数,\(\alpha\):抵抗に対応する変数 - AdaGrad
学習が進んだ方向に対して学習係数を減衰させることで効率を上げる方法です。
$$h\leftarrow h+\frac{\partial L}{\partial W}\cdot\frac{\partial L}{\partial W}$$
$$W\leftarrow W-\eta\frac{1}{\sqrt{h}}\frac{\partial L}{\partial W}$$
\(h\):各方向でパラメータがどれだけ学習してきたか表す変数,\(\cdot\):成分ごとの積 - Adam
MomentumとAdaGradの融合したアイデアを用いた方法です。
それぞれに特徴があり、今のところはすべての問題で優れた方法というものはないようです。
SGDを学んだときは「いかにも自然な更新方法だ」と思っていましたが、損失関数の窪地に向かうという意味でMomentumは確かに自然だし、AdaGradの考え方も効率を上げる意味で有効だなと関心しました。
初期値について
重みの値が大きいモデルは、過学習になってしまっていることが多くあります。
重みが小さいモデルへと学習させたいという意味で、初期重みも小さめの値にするのがよさそうです。
ただし、初期重みをすべて0にしてしまうと、2層以上のネットワークにてパラメータ更新時に計算する偏微分の値が同じになってしまうので、うまく学習が進みません。
初期重みの標準偏差も用いる活性化関数に応じて適した値があるそうです。
適切な標準偏差を持たないパラメータだった場合、勾配の消失が起きて学習が進まなかったり,表現力の制限を受けていいモデルにならなかったりします。
シグモイド関数に対しては標準偏差\(\sqrt{\frac{1}{n}}\)であるXavierの初期値,ReLUに対しては標準偏差\(\sqrt{\frac{2}{n}}\)であるHeの初期値が有効なようです。
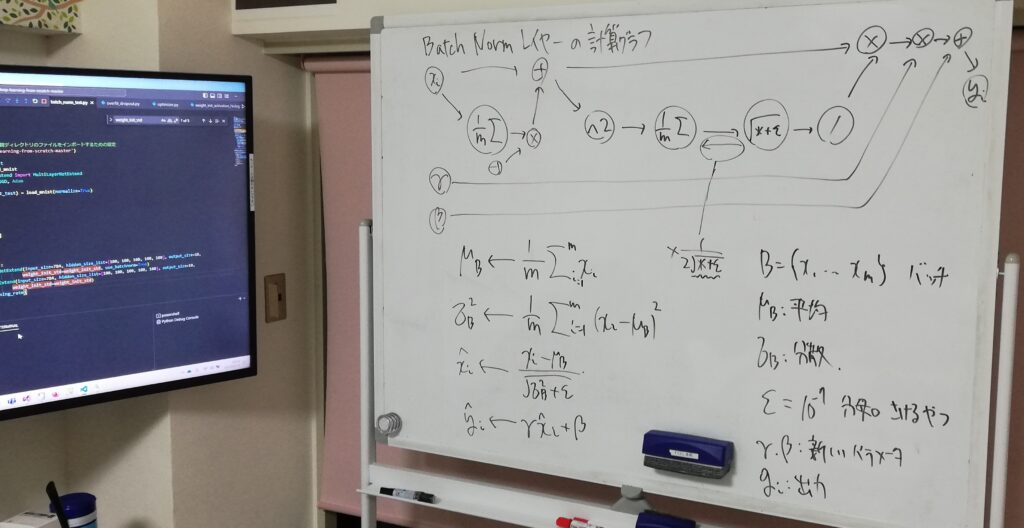
重みの大きさや標準偏差は学習をうまく進める上で重要なので、各層に活性化関数に入れる値の分布を調整するレイヤーを挿入するというアイデアがあります。
それをBatch Normalizationといい、学習を速く進めることができる,初期重みの変化に対して安定であるということを確認しました。
過学習を防ぐために
過学習を抑制するための2種類の方法を学びました。
- Weight decay
損失関数に重みの2乗ノルムを加えることで、大きな重みを持つことにペナルティを与える方法です。
過学習になる原因のひとつである過剰な重みパラメータの大きさを抑制できます。 - Dropout
隠れ層のニューロンをランダムに消去して学習し、運用するときには訓練時に消去した割合を乗算してすべてのニューロンを使う方法です。
いくつかのモデルの平均出力をとることで過学習を抑制するアンサンブル学習モデルに似ています。
ハイパーパラメータの最適化
重みやバイアスのようなパラメータは訓練データで学習していきます。
層やニューロンの数,バッチサイズ,学習係数やWeight decayの係数などはハイパーパラメータであり、学習で更新しませんがモデルの性能に大きく関わるため調整が必要です。
そのために、データを訓練データ,検証データ,テストデータに分けて、ハイパーパラメータの評価を検証データで行います。
ハイパーパラメータを固定しないと学習できないので訓練データを用いることができず、テストデータを用いるとテストに合わせた調整で過学習させてしまうからです。
今のところは、このような部分で人間のエンジニアリングのセンスも必要になっているので、機械学習についてしっかり学んでおくことにも意味があると感じました。
最後に
今回のてくますゼミ記録はChihiroが執筆してみました!
ゼミに参加するだけでも有意義ですが、発表のために予習,資料作成,板書計画をしたり、振り返って記録をまとめたりすると、より理解が深まっていいですね。
次回は畳み込みニューラルネットワークの内容になります。
そろそろこのテキストも終わってしまいますね……
では、また!












